Masked LRMs¶
3D Mesh Editing using Masked LRMs
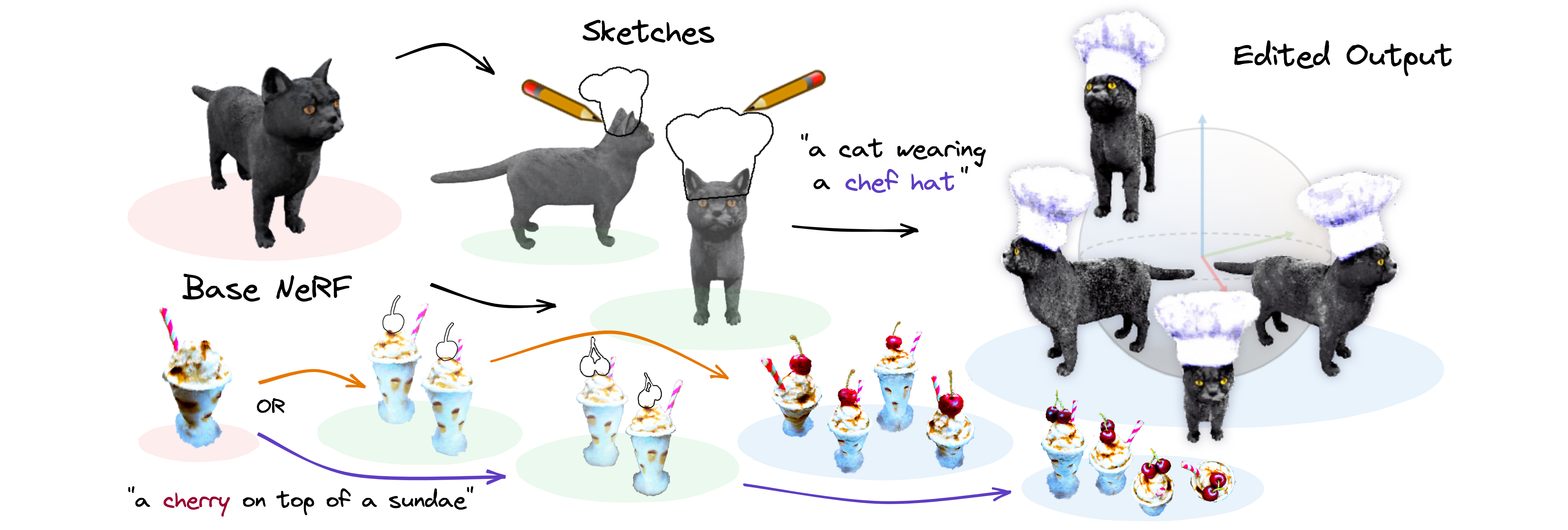
Masked LRMs 把 3D 编辑重新表述成一个“条件重建”问题:模型看到一组带遮挡的多视图和一张干净条件图,需要在保持未遮挡区域几何的同时,把被遮挡区域按条件图重新补出来。
核心问题¶
很多 3D 编辑方法面临两类老问题:
- optimization-based 方法慢,而且梯度噪声大
- multi-view edit 再重建的方法容易遇到跨视角不一致和遮挡歧义
Masked LRMs 的想法是:
既然 LRM 本来就擅长从多视图做重建,那不如直接把编辑建模成 masked reconstruction。
方法框架¶
1. 3D-consistent masking¶
- 训练时不在 2D 上随便抠 mask
- 而是通过一个真实的 3D occluder 渲染出跨视角一致的遮挡区域
- 这样每个视角的 mask 都互相对应
2. Conditional masked reconstruction¶
- 多个输入视图都带遮挡
- 再给一张干净的 canonical conditional image
- 模型学习:保留未遮挡部分,重建遮挡区域
3. 单次前向编辑¶
- 推理时手动定义一个 3D 编辑区域
- 给一张编辑后的条件图
- 模型一次前向就输出编辑后的 mesh
这让它和许多逐样本优化方法相比明显更快。
为什么它重要¶
Masked LRMs 的贡献不只是新任务设定,更重要的是它提出了一种很自然的思路:
- 不把 3D 编辑看成单独设计的新模型
- 而是把它视为 LRM 的“遮挡重建能力”的下游用法
这让 3D 编辑和 3D reconstruction 之间建立了更紧的联系。
关键实验结论¶
重建质量¶
尽管论文主要目标不是重建 benchmark,但模型在 ABO / GSO 上已经达到较强水平:
ABO (8 views): PSNR 28.65, SSIM 0.947, LPIPS 0.078GSO (8 views): PSNR 27.58, SSIM 0.933, LPIPS 0.085
这说明 masked training 并没有明显破坏基本 reconstruction 能力。
编辑速度¶
- 论文报告相对 prior work 可达到
2x - 10x速度优势 - 单次前向就能完成编辑,而不是长时间优化
编辑能力¶
- 由于最终 mesh 来自网络预测,而不是直接优化原网格顶点
- 方法可以做 genus-changing edits,例如加把手、开孔
这一点很关键,因为很多基于几何优化的方法难以做这种非拓扑保持编辑。
与其他路线的关系¶
Masked LRMs 属于典型 2D-guided / lifting-style editing,但比普通 lifting 方法更强调:
- 训练阶段就把“局部遮挡补全”学进去
- 推理时不是先做完整多视图编辑,再重建
- 而是直接让 LRM 在指定区域做条件重建
所以它比一般 multi-view editing pipeline 更贴近“编辑专用的 reconstruction model”。
局限¶
- 仍然依赖用户定义 3D 编辑区域
- 条件图能提供很强控制,但前提是 2D 编辑本身足够合理
- 方法核心还是重建式补全,不是原生 latent 编辑
一句话总结¶
Masked LRMs 的主要意义,是把 3D mesh 编辑变成一个带有 3D 一致遮挡的条件重建任务,让 LRM 通过单次前向完成局部补全式编辑,并支持部分拓扑变化。
评论
评论功能当前未启用。当前站点不依赖 GitHub 评论服务;如果后续需要评论,建议接入自托管评论后端。