TSSR¶
Topology Sculptor, Shape Refiner: Discrete Diffusion Model for High-Fidelity 3D Meshes Generation
TSSR 的独特价值在于:它是 mesh-native 生成中第一个认真对待离散扩散(而非自回归)的方法。在所有同期工作都在优化 AR 序列建模的时候,TSSR 走了一条不同的路。
核心问题¶
自回归方法在 mesh 生成中面临一个固有矛盾:
- Mesh 是一个全局拓扑结构——面和面之间的连接关系是全局的
- AR 模型是逐 token 单向生成——每个 token 只能看到前面的 token
这意味着 AR 模型在生成靠前的 token 时无法参考后续结构,容易导致:
- 拓扑不完整(漏洞、断裂)
- 局部合理但全局不一致
- 生成结尾时难以"收口"
TSSR 的出发点是:如果模型能同时看到所有 token,拓扑一致性问题会更好处理。
方法概述¶
两阶段解耦:拓扑雕刻 + 形状细化¶
TSSR 的核心设计是将 mesh 生成分为两个阶段:
Stage 1: Topology Sculptor(拓扑雕刻)
- 用离散扩散模型生成 mesh 的拓扑结构(面的连接关系)
- 此阶段关注的是"哪些面存在"、"它们怎么连接",不关注精确坐标
- 因为是扩散模型,所有面 token 同时可见,可以做全局拓扑推理
Stage 2: Shape Refiner(形状细化)
- 在已确定的拓扑结构上,细化每个顶点的精确坐标
- 也是基于离散扩散,但工作在坐标空间
这种解耦的好处是:拓扑决策和几何精度可以分别优化,互不干扰。
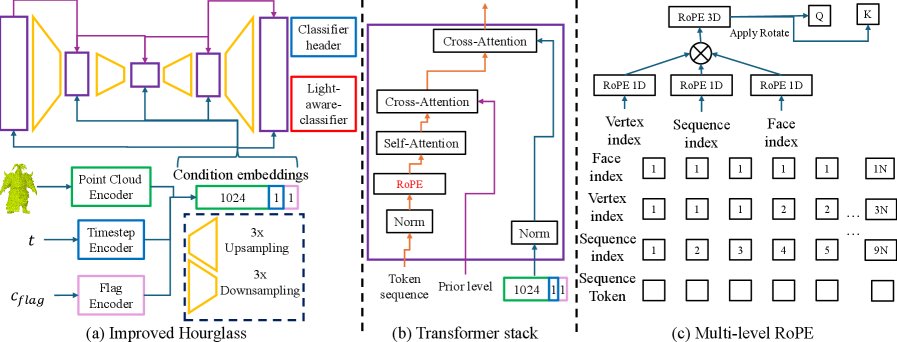
改进的 Hourglass 架构¶
- 采用沙漏结构(encoder-decoder),不同分辨率层之间有信息交换
- 加入了 face-vertex-sequence 三个级别的旋转位置编码(RoPE)
- 双向注意力让每个 token 能看到整个序列
Connection Loss(拓扑约束损失)¶
Connection Loss 是 TSSR 的核心技术贡献之一。它在训练阶段对面间的连接关系施加约束:
- 基本思路:对于预测的 mesh token 序列,检查共享顶点/边的面对之间坐标是否一致
- 形式化:设两个相邻面 \(f_i\) 和 \(f_j\) 共享一条边 \((v_a, v_b)\),Connection Loss 要求两个面中该边的坐标预测完全一致:
其中 \(\mathcal{E}\) 是面邻接图的边集,\(\hat{v}\) 是模型预测的顶点坐标。
- 作用:惩罚不合理的拓扑结构(如孤立面、非流形边、坐标不连续的共享边)
- 这是一个在训练阶段就施加拓扑先验的方法,而非后处理修复
完整损失函数¶
TSSR 两阶段各自的损失:
Stage 1: Topology Sculptor¶
- \(\mathcal{L}_{DDM}^{topo}\):离散扩散模型的标准 token prediction 损失(在拓扑 token 上),类似 masked language modeling
- \(\mathcal{L}_{conn}\):Connection Loss,约束面间连接关系
Stage 2: Shape Refiner¶
- 在已确定的拓扑结构上,对顶点坐标 token 做离散扩散去噪
- 此阶段拓扑已固定,不再需要 Connection Loss
架构细节¶
Improved Hourglass Architecture¶
- 编码路径:逐步降采样 mesh token 序列,提取多尺度特征
- 解码路径:逐步上采样,在每一级与编码路径的对应层做 skip connection
- 注意力机制:双向全注意力(区别于 AR 的因果注意力),每个 token 可以看到整个序列
- 位置编码:face-vertex-sequence 三级 RoPE
- face-level RoPE:编码面的全局序号
- vertex-level RoPE:编码面内顶点的局部序号(0, 1, 2)
- sequence-level RoPE:编码 token 在整个序列中的位置
- Hourglass bottleneck:在最低分辨率层进行全局信息聚合,使得远距离面的拓扑关系能被捕捉
规模与性能¶
TSSR 报告的关键数字:
- 最多 10,000 面的 mesh 生成(是 Nautilus 5000 面的 2 倍)
- 空间分辨率 1024^3
- 因为扩散模型并行去噪,不需要像 AR 那样逐 token 生成
训练配置¶
- 训练数据:Objaverse 过滤子集(高质量 artist mesh)
- 坐标量化分辨率:\(1024^3\)(10-bit per axis)
- 去噪步数:论文中对 100-1000 步范围做了实验
- 两阶段分别训练:先训练 Topology Sculptor 收敛,再训练 Shape Refiner
定量实验¶
论文在 Objaverse 子集上报告了与 MeshGPT、Nautilus 等 AR 方法的对比:
| 指标 | TSSR 表现 |
|---|---|
| 面数上限 | 10,000 面(AR 方法通常 ~5,000) |
| 空间分辨率 | \(1024^3\)(高于多数 AR 方法的 \(128^3\)) |
| 拓扑完整性 | 连通分量数接近 GT,优于 AR baseline |
| Chamfer Distance | 与 Nautilus 可比 |
| 生成速度 | 并行去噪,在大面数时比 AR 更快 |
定性发现¶
- 离散扩散在处理对称结构(椅子腿、桌面边缘)时表现更稳定,因为可以全局推理
- Connection Loss 有效减少了面间裂缝(ablation 表明去除后拓扑质量明显下降)
- 两阶段解耦使得拓扑错误不会传播到几何精度上
为什么值得关注¶
1. 离散扩散在 mesh 上的可行性验证¶
在此之前,mesh-native 生成几乎全是 AR 路线(MeshGPT → Nautilus → BPT → FACE)。TSSR 证明了离散扩散也是可行的,而且在拓扑质量上有天然优势。
2. 两阶段解耦的设计哲学¶
把拓扑和几何分开处理,是一个值得借鉴的思路。拓扑决策更像离散组合问题,几何精度更像连续优化问题,分开处理更合理。
3. 面数上限的又一次提升¶
10,000 面是目前 mesh-native 生成方法报告的最高数字之一,进一步缩小了与实际生产需求之间的差距。
与其他工作的关系¶
相比 MeshGPT / Nautilus / BPT(AR 路线)¶
- AR 方法逐 token 单向生成,天然难以做全局拓扑推理
- TSSR 的离散扩散允许全局并行推理,对拓扑一致性更友好
- 但 AR 方法在条件生成和序列灵活性上有优势
相比 MeshRipple¶
- MeshRipple 仍然是 AR,但通过 frontier-aware BFS 和 global memory 部分缓解了拓扑问题
- TSSR 从模型架构层面根本性地解决了"看不到全局"的问题
相比 latent diffusion 路线(TRELLIS、OctFusion)¶
- TRELLIS、OctFusion 在隐空间做扩散,再转成 mesh
- TSSR 直接在 mesh token 空间做扩散,不需要 latent → mesh 的转换步骤
优势与局限¶
优势¶
- 离散扩散实现全局并行推理,拓扑一致性更好
- 两阶段解耦设计合理(拓扑 → 几何)
- 面数上限达到 10,000
- Connection Loss 在训练时就施加拓扑约束
局限¶
- 离散扩散的采样质量依赖去噪步数,步数多则慢
- 两阶段意味着 pipeline 更复杂
- 尚未在大型数据集(如 Objaverse 全集)上验证可扩展性
- 论文发表时尚未被顶会接收(preprint 阶段)
一句话总结¶
TSSR 用离散扩散取代自回归来做 mesh-native 生成,通过拓扑雕刻和形状细化两阶段解耦,实现了 10,000 面、1024^3 分辨率的高保真 mesh 生成,证明了扩散模型在 mesh 拓扑建模上的可行性。